Cum folosim A2A în practică la CAI Technology (și de ce MCP nu e suficient)
MCP standardizează tools, A2A standardizează cooperarea între agenți. La CAI rulăm 12 agenți Demeter coordonați prin Iris peste un layer MCP cu 15 tools. Iată cum și de ce, cu exemple concrete din producție.
Cum folosim A2A în practică la CAI Technology (și de ce MCP nu e suficient)
În ultimii doi ani, majoritatea conversațiilor despre AI s-au concentrat pe modele din ce în ce mai mari. În practică, când construiești sisteme reale care fac muncă zilnică pentru oameni, problema nu mai e „cât de bun e modelul”, ci cum organizezi inteligența în sistem.
La CAI Technology rulăm două straturi diferite, ambele live, ambele necesare: MCP ca interfață standardizată prin care un agent ajunge la unelte, și A2A ca protocol prin care mai mulți agenți specializați colaborează între ei. Articolul de față arată exact unde le folosim, ce face fiecare și de ce niciunul singur nu e suficient.
TL;DR
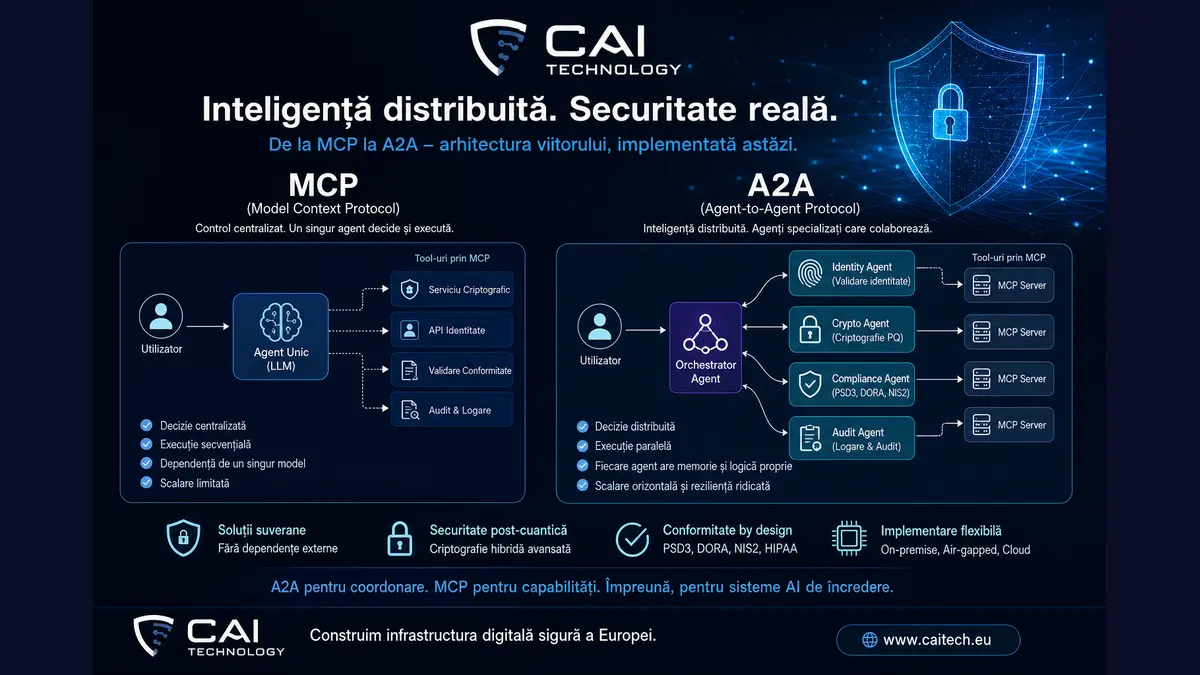
- MCP = un creier, multe tools, interfață uniformă. Excelent pentru standardizare; insuficient pentru fluxuri complexe.
- A2A = mai multe creiere specializate care comunică prin evenimente. Permite paralelism, izolare a erorilor și evoluție independentă.
- La CAI rulăm ambele simultan: A2A coordonează (Iris orchestrator + 12 agenți Demeter + cai4notify pub/sub), MCP livrează capabilitățile (CAI Hub cu 15 tools).
- Beneficii măsurate în producție: cost LLM redus prin model-routing per task, evoluție independentă a fiecărui agent, transparență totală pentru utilizator.
- Aceeași stivă o livrăm la clienți: agenți specializați pe verticala lor, coordonați prin orchestrator, transparenți la decizie.
De unde pleacă lucrurile: MCP
MCP (Model Context Protocol) e standardul prin care un model LLM apelează unelte externe în mod uniform. În loc să scrii integrări ad-hoc pentru fiecare serviciu, expui un MCP server care declară un set de tools, iar orice agent compatibil le poate folosi.
La noi, serverul intern CAI Hub expune azi 15 MCP tools peste infrastructura proprie: query Postgres, citire inventory servere, creare proposals, citire events, și altele. Un singur agent care vorbește MCP poate astfel:
- să caute un host în inventory
- să verifice ce containere rulează pe el
- să propună o acțiune
- să o înregistreze în audit
Toate fără cod custom de integrare. MCP e excelent pentru standardizare.
Dar — și aici începe limita — MCP nu spune nimic despre cine face decizia. Are un singur creier care apelează tools. Pentru task-uri scurte, liniare, asta e suficient. Pentru fluxuri reale, nu.
Unde nu mai e suficient
Un mail care intră în inbox-ul unei companii nu e un task simplu. Trebuie:
- citit și înțeles (limbă, ton, context, fir de discuție)
- corelat cu mailuri trimise (e deja un răspuns? cine a răspuns?)
- clasificat (urgent? informativ? cerere concretă?)
- pregătit ca draft pentru un eventual răspuns
- trimis în UI cu opțiuni clare pentru utilizator
- arhivat sau curățat dacă e duplicat / spam / expirat
Dacă încerci să bagi tot asta într-un singur „super-agent” care primește mailul și „face totul”, în câteva săptămâni ai un monolit AI cu logică imposibil de schimbat fără să strici altceva. Probleme tipice: decizii înghesuite în prompt, costuri crescute pentru orice acțiune (rulezi modelul mare pentru fiecare sub-task), erori care contaminează tot fluxul, imposibilitate de a rula task-uri în paralel.
Aici intervine A2A
A2A (Agent-to-Agent) înseamnă că responsabilitatea e împărțită între agenți specializați care comunică între ei după reguli clare. Niciun agent nu „face totul”. Există un orchestrator care primește cererea și decide cine o rezolvă și în ce ordine.
În platforma noastră operațională, Demeter, rulează azi 12 agenți specializați, fiecare cu propriul prompt, propriile reguli și propriile tools:
- Email Guardian — triază mailurile și propune drafturi
- Email Janitor — curăță inbox-ul (vechi, spam expirat, duplicate)
- Calendar Concierge — găsește slot-uri, propune întâlniri, evită conflicte
- Document Reader (RAG) — răspunde la întrebări peste folder-ul tău de fișiere
- Document Writer — scrie documente noi cu citații verificabile
- Contract Reviewer — analizează clauze și semnalează riscuri
- Compliance Monitor — urmărește modificări legislative și impactul lor
- Customer Follow-up — detectează lipsa de răspuns și propune urmărirea
- Invoice Reader — extrage date din facturi PDF
- Meeting Secretary — scrie minute după întâlniri
- Project Tracker — agregă status-uri din mailuri și conversații
- Tender Watcher — scanează licitații publice
Peste ei, Iris e orchestratorul. Userul scrie pe Telegram sau în UI: „uită-te la mailul de la X și pregătește răspuns” — Iris înțelege intenția, identifică agentul potrivit (Email Guardian), îi cere triajul, primește draftul, îl trimite înapoi userului pentru aprobare.
Pentru comunicarea efectivă între agenți folosim un layer publish/subscribe propriu (pub/sub asincron). Un agent publică un eveniment (email_triaged, proposal_ready, incident_detected), alți agenți care s-au abonat reacționează asincron. Nu există apel direct, nu există cuplare strânsă. Un agent picat nu blochează restul.
Diferența reală, în două propoziții
MCP standardizează cum un agent ajunge la unelte. Un creier, multe tools, interfață uniformă.
A2A standardizează cum mai mulți agenți cooperează între ei. Mai multe creiere, decizii distribuite, comunicare prin evenimente.
În operațiunile zilnice CAI, ambele rulează simultan: A2A coordonează (Iris ↔ Demeter ↔ pub/sub events), MCP livrează capabilitățile (CAI Hub tools). Nu e o alegere ori-ori; e o stivă cu două niveluri.
Ce câștigi concret cu A2A
- Execuție paralelă reală. Email Guardian triază mailuri în timp ce Calendar Concierge răspunde la o cerere de slot. Un singur agent ar fi serializat ambele.
- Izolarea erorilor. Dacă LLM-ul cade pentru un singur agent, restul continuă. Săptămâni cu rate de eroare diferite per agent — nimic nu se propagă lateral.
- Cost controlat. Nu folosim modelul cel mare pentru tot. Email Guardian rulează un model mediu specializat pe email RO. Calendar Concierge poate folosi un model mai mic pentru aritmetică pe ore.
- Evoluție independentă. Putem rescrie Email Guardian fără să atingem Calendar Concierge. Versiuni independente, deploy-uri independente, contracte doar pe evenimente publicate.
- Transparență pentru user. În UI vezi exact ce agent a făcut ce — timestamp, decizie, motiv. Asta nu poți avea cu un monolit.
De la operațiunile noastre, la operațiunile tale
Aceeași stivă pe care o rulăm intern, o livrăm la clienți. Diferă verticala, nu arhitectura:
- Pentru o firmă de avocatură — agenți specializați pe contracte, citație juridică, conformitate, confidențialitate, coordonați de un orchestrator care înțelege fluxul intern al firmei.
- Pentru o companie din procurement — agenți care monitorizează licitații, parsează caiete de sarcini, verifică furnizori, generează deviz și pregătesc oferta finală.
- Pentru un departament IT/SOC — agenți care triază alertele, corelează evenimente, propun acțiuni de remediere, toate sub aprobarea umană.
În toate cazurile, principiul rămâne același: distribui inteligența pe responsabilități clare, păstrezi orchestratorul ca punct unic de decizie umană, instrumentezi totul prin MCP.
Cum lucrăm cu tine
Discovery scurt în 2 săptămâni: identificăm 1-3 fluxuri repetitive cu impact ridicat, construim un MVP cu 2-3 agenți coordonați, livrăm cu acces la dashboard-ul de transparență. După MVP, decizia e a ta dacă scalăm la mai mulți agenți sau la mai multe departamente.
Stack-ul e al tău: poți rula totul on-prem, în cloud-ul tău sau hybrid. Modelele LLM pot fi locale (Qwen, Mistral) sau externe (Claude, GPT) — alegerea o faci în funcție de buget, suveranitate de date și performanță. Niciun lock-in.
Concluzie
Pe măsură ce sistemele AI devin parte din infrastructura operațională, arhitectura contează mai mult decât modelul în sine. Direcția noastră la CAI Technology e clară: nu centralizăm inteligența, o distribuim. Coordonăm cu A2A, capabilităm cu MCP, rulăm la vedere fiecare decizie.
Pentru sisteme reale, sigure și scalabile, nu ai nevoie de un super-creier. Ai nevoie de o colaborare controlată între componente care fiecare știe să facă bine un singur lucru.
Vrei să vezi cum arată asta pentru afacerea ta?
Programează un discovery de 30 de minute și îți arătăm exact ce 2-3 agenți ar avea sens să rulezi în următoarele 6 săptămâni — pe stack-ul tău, cu datele tale, cu transparență totală. Fără slide-uri, doar exemple concrete.
→ Contactează-ne sau scrie la tehnic@caitech.ro
→ Vezi și serviciile noastre AI/ML și produsele CAI deja live în producție.