How we use A2A in practice at CAI Technology (and why MCP isn't enough)
MCP standardises tools, A2A standardises cooperation between agents. At CAI we run 12 Demeter agents coordinated through Iris over an MCP layer with 15 tools. Here's how and why, with concrete production examples.
How we use A2A in practice at CAI Technology (and why MCP isn’t enough)
Over the past two years, most AI conversations have focused on bigger and bigger models. In practice, when you build real systems that handle daily work for people, the question stops being „how good is the model” and becomes how do you organise intelligence in the system.
At CAI Technology we run two distinct layers, both live, both necessary: MCP as the standardised interface through which an agent reaches its tools, and A2A as the protocol through which several specialised agents cooperate. This article shows exactly where we use them, what each does, and why neither alone is enough.
TL;DR
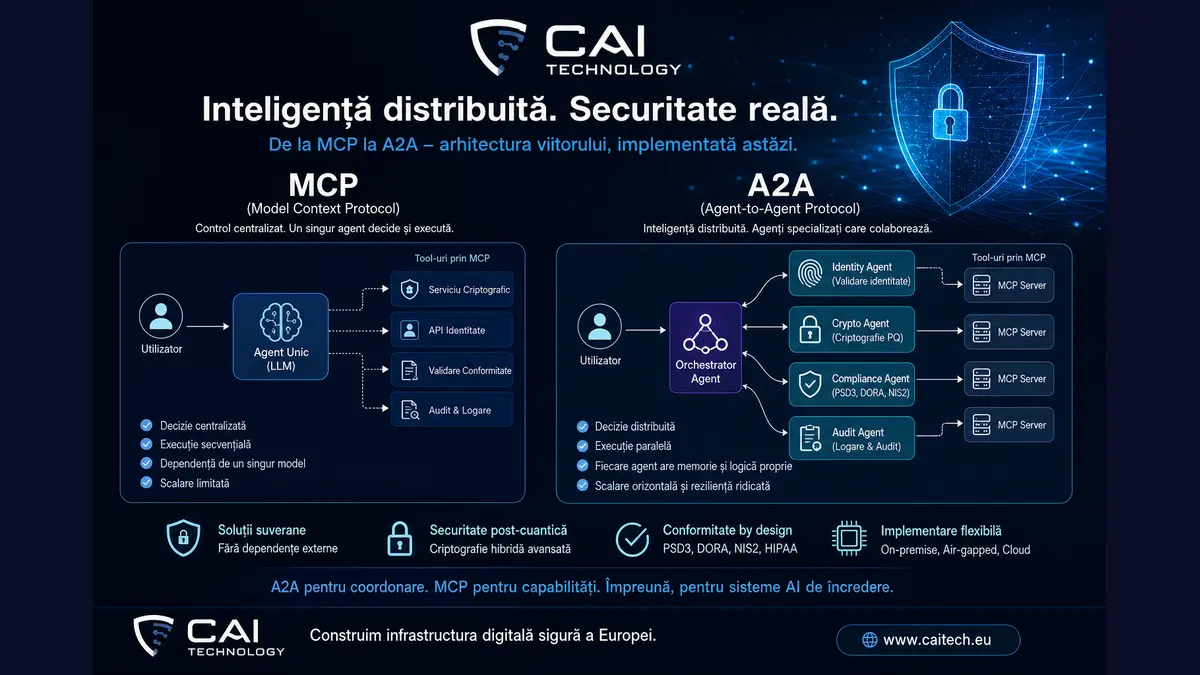
- MCP = one brain, many tools, uniform interface. Excellent for standardisation; insufficient for complex flows.
- A2A = several specialised brains that communicate through events. Enables parallelism, error isolation and independent evolution.
- At CAI we run both simultaneously: A2A coordinates (Iris orchestrator + 12 Demeter agents + pub/sub events), MCP delivers the capabilities (CAI Hub with 15 tools).
- Production benefits we measure: lower LLM cost via per-task model routing, independent evolution per agent, full transparency for the user.
- We deliver the same stack to clients: agents specialised for their vertical, coordinated through an orchestrator, transparent at every decision.
Where it starts: MCP
MCP (Model Context Protocol) is the standard through which an LLM model invokes external tools uniformly. Instead of writing ad-hoc integrations for every service, you expose an MCP server that declares a set of tools, and any compatible agent can use them.
In our case, the internal CAI Hub server exposes 15 MCP tools today over our own infrastructure: query Postgres, read server inventory, create proposals, read events, and others. A single MCP-aware agent can then:
- look up a host in inventory
- check what containers run on it
- propose an action
- record it in audit
All of that, with no custom integration code. MCP is excellent for standardisation.
But — and this is where the limit shows — MCP says nothing about who makes the decision. There is one brain calling tools. For short, linear tasks, that’s enough. For real flows, it isn’t.
Where it stops being enough
An email arriving in a company inbox isn’t a simple task. It needs to be:
- read and understood (language, tone, context, thread)
- correlated with sent mail (is it already a reply? who answered?)
- classified (urgent? informational? concrete request?)
- prepared as a draft for a possible reply
- presented in the UI with clear options for the user
- archived or cleaned up if it’s a duplicate / spam / expired
If you cram all of that into a single „super-agent” that takes the email and „does everything”, in a few weeks you have an AI monolith with logic that’s impossible to change without breaking something else. Typical issues: decisions stuffed into the prompt, rising costs for any action (you run the big model for every sub-task), errors that contaminate the whole flow, no ability to run tasks in parallel.
This is where A2A comes in
A2A (Agent-to-Agent) means responsibility is split between specialised agents that talk to each other through clear rules. No single agent „does everything”. There’s an orchestrator that takes the request and decides who solves it and in what order.
In our operational platform, Demeter, 12 specialised agents run today, each with its own prompt, rules and tools:
- Email Guardian — triages mail and proposes drafts
- Email Janitor — cleans the inbox (old, expired spam, duplicates)
- Calendar Concierge — finds slots, proposes meetings, avoids conflicts
- Document Reader (RAG) — answers questions over your file folder
- Document Writer — drafts new documents with verifiable citations
- Contract Reviewer — analyses clauses, flags risks
- Compliance Monitor — tracks legislative changes and their impact
- Customer Follow-up — detects missing replies, proposes follow-up
- Invoice Reader — extracts data from PDF invoices
- Meeting Secretary — writes minutes after meetings
- Project Tracker — aggregates status from emails and conversations
- Tender Watcher — scans public procurement
Above them, Iris is the orchestrator. The user writes on Telegram or in the UI: „look at the email from X and prepare a reply” — Iris understands the intent, picks the right agent (Email Guardian), asks it to triage, receives the draft, sends it back to the user for approval.
For actual inter-agent communication we use our own publish/subscribe layer (async pub/sub). One agent publishes an event (email_triaged, proposal_ready, incident_detected), other agents that subscribed react asynchronously. No direct calls, no tight coupling. One agent down doesn’t block the rest.
The real difference, in two sentences
MCP standardises how an agent reaches its tools. One brain, many tools, uniform interface.
A2A standardises how several agents cooperate. Many brains, distributed decisions, event-based communication.
In daily CAI operations, both run simultaneously: A2A coordinates (Iris ↔ Demeter ↔ pub/sub events), MCP delivers capabilities (CAI Hub tools). It’s not an either/or choice; it’s a two-level stack.
What you actually gain with A2A
- Real parallel execution. Email Guardian triages mail while Calendar Concierge answers a slot request. A single agent would have serialised both.
- Error isolation. If the LLM fails for one agent, the others keep going. We’ve had weeks with different per-agent error rates — nothing propagates sideways.
- Controlled cost. We don’t use the big model for everything. Email Guardian runs a medium model specialised on RO email. Calendar Concierge can use a smaller one for hour-arithmetic.
- Independent evolution. We can rewrite Email Guardian without touching Calendar Concierge. Independent versions, independent deploys, contracts only on published events.
- Transparency for the user. In the UI you see exactly what each agent did — timestamp, decision, reason. You can’t have that with a monolith.
From our operations to yours
The same stack we run internally is what we deliver to clients. The vertical changes; the architecture doesn’t:
- For a law firm — agents specialised in contracts, legal citation, compliance, confidentiality, coordinated by an orchestrator that understands the firm’s internal flow.
- For a procurement company — agents that monitor tenders, parse specifications, vet suppliers, generate quotes and prepare the final bid.
- For an IT/SOC team — agents that triage alerts, correlate events, propose remediation actions, all under human approval.
In every case, the principle stays the same: distribute intelligence by clear responsibilities, keep the orchestrator as a single point of human decision, instrument everything via MCP.
How we work with you
A short 2-week discovery: we identify 1-3 high-impact repetitive flows, build an MVP with 2-3 coordinated agents, deliver it with access to the transparency dashboard. After the MVP, you decide whether to scale to more agents or more departments.
The stack is yours: you can run it fully on-prem, in your own cloud, or hybrid. LLM models can be local (Qwen, Mistral) or external (Claude, GPT) — choose based on budget, data sovereignty and performance. No lock-in.
Conclusion
As AI systems become part of operational infrastructure, architecture matters more than the model itself. Our direction at CAI Technology is clear: we don’t centralise intelligence, we distribute it. We coordinate with A2A, capability-load through MCP, and run every decision in plain sight.
For real systems — secure and scalable — you don’t need a super-brain. You need controlled cooperation between components that each know how to do one thing well.
Want to see what this looks like for your business?
Book a 30-minute discovery and we’ll show you exactly which 2-3 agents would make sense to run over the next 6 weeks — on your stack, with your data, with full transparency. No slides, just concrete examples.
→ Contact us or write to tehnic@caitech.ro
→ See also our AI/ML services and CAI products already live in production.